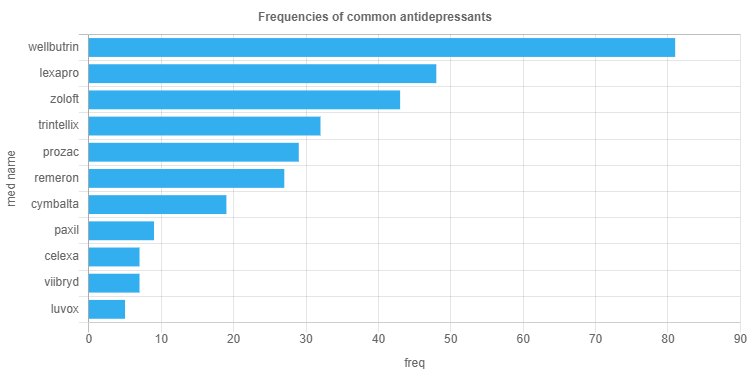
*NOTE: I have manually modified some of the equations produced by ChatGPT, such as adding a t-1 subscript
Hello, please tell me what is ChatGPT?
ChatGPT is a variant of the GPT (Generative Pre-training Transformer) language model that was specifically designed for use in chatbots and conversational AI systems. It is trained on a large dataset of human-human conversations and is able to generate human-like responses to user input. ChatGPT can be used to build chatbots that can hold natural language conversations with users, helping businesses and organizations automate customer service, sales, and other types of interactions.
Like other GPT models, ChatGPT is a transformer-based language model that uses attention mechanisms to process and generate text. It is trained using a combination of supervised learning, in which the model is given labeled examples of conversation, and unsupervised learning, in which the model is trained to predict the next word in a sequence based on the context of the words that come before it. This allows ChatGPT to learn the patterns and structure of human conversation and generate appropriate responses to user input.
I would like to learn more about machine learning, let’s start with the concept of neural networks. Please explain the concept of a neural network.
A neural network is a type of machine learning model that is inspired by the structure and function of the human brain. It is composed of a large number of interconnected “neurons,” which are simple processing units that receive input, transform it, and produce output.
In a neural network, the input data is fed through a series of hidden layers, each of which is made up of a large number of neurons. These hidden layers process the input data using weighted connections between the neurons. The weights of these connections are adjusted during the training process, allowing the neural network to “learn” from the input data.
The output of the neural network is produced by the output layer, which is also made up of a number of neurons. The output layer takes the processed data from the hidden layers and produces the final output of the neural network.
Neural networks can be used for a wide variety of machine learning tasks, including classification, regression, and clustering. They are particularly powerful for tasks that require the processing of large amounts of data or the detection of patterns and relationships in data that are not immediately apparent.
Overall, the concept of a neural network is a key element of machine learning and is used in many different applications and industries.
How does a neural network look in terms of mathematical equations? What is the architecture?
The architecture of a neural network refers to the way that the neurons are organized and connected within the network. A typical neural network consists of an input layer, one or more hidden layers, and an output layer. The input layer receives the raw input data, and the output layer produces the final output of the network. The hidden layers are located between the input and output layers and are responsible for processing the input data and producing intermediate output that is passed on to the output layer.
In terms of mathematical equations, the computation performed by a neural network can be represented by a series of matrix multiplications and element-wise non-linear functions (also called activation functions).
For example, consider a neural network with one hidden layer and an input layer with m inputs and an output layer with n outputs. Let’s say that the input data is represented by a matrix X with dimensions m x N (where N is the number of data points) and the weights between the input layer and the hidden layer are represented by a matrix W1 with dimensions m x p (where p is the number of neurons in the hidden layer). The output of the hidden layer is then given by:
h = f(XW1 + b1)
where f is the activation function and b1 is a bias term.
The weights between the hidden layer and the output layer are represented by a matrix W2 with dimensions p x n, and the final output of the neural network is given by:
y = f(hW2 + b2)
where b2 is a bias term.
This is just a simple example, but it illustrates the basic idea of how a neural network can be represented mathematically. In practice, neural networks can have many more layers and a much larger number of neurons, and the equations can become quite complex. However, the basic idea of using matrix multiplications and non-linear activation functions to transform the input data and produce output remains the same.
What exactly do you mean by activation function? What are some examples of such functions?
An activation function is a mathematical function that is applied to the output of a neuron in a neural network. It determines whether the neuron will “fire” and produce an output, or whether it will remain inactive. Activation functions are a key component of neural networks because they allow the network to learn non-linear relationships in the data.
There are many different activation functions that can be used in neural networks, each with its own properties and characteristics. Some common examples include:
Sigmoid: The sigmoid function is a smooth, S-shaped curve that maps any input value to a value between 0 and 1. It is often used in the output layer of a binary classification neural network because it can produce a probability-like output.
Tanh: The tanh (hyperbolic tangent) function is also a smooth, S-shaped curve, but it maps input values to a range of -1 to 1. It is similar to the sigmoid function, but it allows for negative output values as well.
ReLU (Rectified Linear Unit): The ReLU function is a piecewise linear function that maps negative input values to 0 and positive input values to the same value. It is a simple and efficient activation function that has been widely adopted in many neural network architectures.
Leaky ReLU: The leaky ReLU function is a variant of the ReLU function that allows a small negative slope for negative input values. This can help prevent the “dying ReLU” problem, in which some neurons in the network become inactive and stop producing output.
Softmax: The softmax function is a generalization of the sigmoid function that is often used in the output layer of a neural network for multi-class classification. It maps the input values to a probability distribution over the different classes, such that the sum of the probabilities is 1.
These are just a few examples of the many activation functions that are used in neural networks. The choice of activation function can have a significant impact on the performance of the network, and different activation functions may be better suited for different types of tasks and data.
So how would I choose an activation function then? Would each layer have a different activation function?
The choice of activation function can have a significant impact on the performance of a neural network, and it is an important design decision that can affect the network’s ability to learn from the data and generalize to new examples.
There is no one-size-fits-all activation function that is best for all situations, and it is often necessary to experiment with different activation functions to find the one that works best for a particular task. In general, it can be helpful to consider the properties of the activation function and how they align with the characteristics of the data and the goals of the task.
For example, if you are building a neural network for a binary classification task, you may want to use a sigmoid or a tanh activation function in the output layer, since these functions can produce a probability-like output between 0 and 1. On the other hand, if you are building a neural network for a multi-class classification task, you may want to use a softmax activation function in the output layer, since it can produce a probability distribution over the different classes.
As for the hidden layers of the network, ReLU and its variants (such as Leaky ReLU) are often a good choice, since they are simple and efficient and have been shown to work well in a wide range of tasks. However, other activation functions may also be suitable, depending on the characteristics of the data and the specific goals of the task.
In general, it is possible to use different activation functions in different layers of a neural network, and this can sometimes be helpful to improve the network’s performance. However, it is also important to be mindful of the complexity of the network and to avoid adding unnecessary complexity that could harm the network’s ability to learn effectively.
So once I have my data inputs, my data outputs, and I choose my activation functions, how do I choose the number of layers in my neural network?
The number of layers in a neural network, as well as the number of neurons in each layer, are important design choices that can impact the network’s ability to learn from the data and generalize to new examples. In general, the more layers and neurons a network has, the more capacity it has to learn from the data. However, too many layers and neurons can also make the network more prone to overfitting, which is when the network performs well on the training data but poorly on new, unseen examples.
There is no hard and fast rule for choosing the number of layers and neurons in a neural network, and it is often necessary to experiment with different configurations to find the one that works best for a particular task. However, there are a few guidelines that you can follow to help you make informed decisions:
- Start with a small number of layers and neurons and gradually increase them until you see improvements in the network’s performance. This can help you avoid the problem of overfitting, since a smaller network is less likely to overfit the data.
- Consider the complexity of the task and the amount of data you have available. For more complex tasks or larger datasets, you may need a deeper network (i.e., one with more layers) to learn effectively. On the other hand, for simpler tasks or smaller datasets, a shallower network may be sufficient.
- Experiment with different architectures and compare the performance of the different models. This can help you identify the best-performing configuration for your task.
Ultimately, the choice of the number of layers and neurons in a neural network is a trade-off between model capacity and generalization. You want to choose a configuration that has enough capacity to learn from the data, but not so much that it overfits the data. Finding the right balance can require some experimentation and trial and error, but with the right approach, you can build a neural network that performs well on your task.
Once I will choose the number of layers, the number of neurons in each layers, the activation functions, how do I train the model then? How will the weights be calculated?
To train a neural network, you need to adjust the weights of the connections between the neurons in such a way that the output of the network is as close as possible to the desired output for a given set of inputs. The process of adjusting the weights to minimize the difference between the predicted output and the desired output is known as optimization.
There are several optimization algorithms that can be used to train a neural network, each with its own pros and cons. Some common optimization algorithms include:
- Stochastic Gradient Descent (SGD): SGD is a simple and widely-used optimization algorithm that involves updating the weights of the network based on the gradient of the loss function with respect to the weights. The loss function is a measure of how well the network is doing at predicting the desired output given the input data, and the gradient is a vector that points in the direction of the steepest increase in the loss function. SGD involves repeatedly updating the weights in the opposite direction of the gradient, in an attempt to minimize the loss function and improve the performance of the network.
- Adam (Adaptive Moment Estimation): Adam is a variant of SGD that uses an adaptive learning rate, which means that the step size for updating the weights is adjusted based on the past gradient information. Adam tends to be more efficient and require fewer hyperparameter tuning compared to SGD.
- Mini-batch gradient descent: Mini-batch gradient descent is a variant of SGD that involves dividing the training data into small batches and updating the weights based on the average of the gradients of the loss function for each batch. This can be more efficient than SGD, especially for large datasets, since it allows the network to learn from the data more quickly.
- RProp (Resilient Backpropagation): RProp is a variant of SGD that uses a heuristic approach to adjust the learning rate for each weight individually, based on the past gradient information. It is generally faster and more efficient than SGD, and it is often used in large-scale neural network training.
Please explain stochastic gradient descent further, include equations
Stochastic Gradient Descent (SGD) is a widely-used optimization algorithm for training neural networks and other machine learning models. It involves updating the weights of the model based on the gradient of the loss function with respect to the weights. The loss function is a measure of how well the model is doing at predicting the desired output given the input data, and the gradient is a vector that points in the direction of the steepest increase in the loss function.
SGD works by iteratively updating the weights of the model in the opposite direction of the gradient, in an attempt to minimize the loss function and improve the performance of the model. The update rule for SGD can be expressed as follows:
w = w – alpha * gradient
where w is the weight of the model, alpha is the learning rate (a hyperparameter that controls the step size for updating the weights), and gradient is the gradient of the loss function with respect to the weight.
The learning rate is an important hyperparameter in SGD, and it determines the step size for updating the weights. A larger learning rate can lead to faster convergence, but it can also make the optimization process more unstable. On the other hand, a smaller learning rate can lead to slower convergence, but it can also make the optimization process more stable.
SGD can be implemented in a number of ways, and it is often used in conjunction with other techniques, such as mini-batch gradient descent or momentum, to improve the efficiency and stability of the optimization process.
You also mentioned ADAM – Adaptive Moment Estimation, how does this algorithm differ from SGD? Please provide equations.
Adam (Adaptive Moment Estimation) is a variant of Stochastic Gradient Descent (SGD) that uses an adaptive learning rate, which means that the step size for updating the weights is adjusted based on the past gradient information. Adam is a popular optimization algorithm that is often used to train neural networks and other machine learning models.
One of the key differences between Adam and SGD is that Adam uses an exponentially weighted average of the past gradients to scale the learning rate, rather than a fixed learning rate as in SGD. This allows Adam to automatically adjust the learning rate based on the characteristics of the data and the optimization process, which can lead to faster convergence and better performance.
The update rule for Adam can be expressed as follows:
m = beta1 * m_t-1 + (1 – beta1) * gradient
v = beta2 * v_t-1 + (1 – beta2) * gradient^2
w = w_t-1 – alpha * m / (sqrt(v) + epsilon)
where w is the weight of the model, alpha is the learning rate (a hyperparameter that controls the step size for updating the weights), m and v are the exponentially weighted averages of the past gradients and squared gradients, respectively, beta1 and beta2 are hyperparameters that control the decay rate of the moving averages, and epsilon is a small value that is used to prevent division by zero.
Adam uses two moving averages, one for the gradients and one for the squared gradients, which allows it to incorporate both the mean and the variance of the past gradients into the learning rate. This can help to stabilize the optimization process and prevent oscillations or divergences.
You also listed RProp (Resilient Backpropagation) as an optimization algorithms, please explain RProp with equations.
Resilient backpropagation (RProp) is an optimization algorithm used in artificial neural networks for training supervised learning models. It is an extension of the backpropagation algorithm that aims to improve the convergence speed of the training process by adapting the learning rate for each weight in the network during training.
Like backpropagation, RProp uses the gradient of the loss function to update the weights of the network. The gradient is calculated using the chain rule and the weights are updated using the following equation:
weight(t+1) = weight(t) – learning_rate * gradient(t)
In backpropagation, the learning rate is a fixed hyperparameter that is set before training. In RProp, the learning rate is not fixed and is instead adapted for each weight based on the sign of the gradient. In RProp, the learning rate for each weight in the network is updated individually, based on the sign of the gradient of the loss function with respect to that weight. This means that the learning rate for each weight is updated individually based on the convergence of that weight, rather than being updated based on the convergence of all weights in the network. This can improve the convergence speed of the training process, as the learning rate can be adjusted according to the convergence of each weight.
The learning rate is updated using the following equation:
learning_rate(i)_t+1 = learning_rate(i)_t – step_size(i)_t-1 * sng (dE_t-1 / dw(i)_t-1 )
I have also often heard the AdaGrad optimizer mentioned, please explain that to me
In AdaGrad, the learning rate is not fixed and is instead adapted for each weight based on the history of the gradients of the loss function with respect to that weight. Specifically, the learning rate is adjusted based on the sum of the squares of the gradients of the loss function with respect to the weight.
The learning rate for each weight is updated using the following equation:
learning_rate(t+1) = learning_rate(t) / sqrt(sum(gradient(t)^2))
where sum(gradient(t)^2) is the sum of the squares of the gradients of the loss function with respect to the weight up to time t.
This means that the learning rate for each weight is inversely proportional to the sum of the squares of the gradients of the loss function with respect to that weight. This has the effect of decreasing the learning rate for weights that have had large gradients in the past, and increasing the learning rate for weights that have had small gradients in the past.
I have also heard of gradient boosting, explain that
Gradient boosting is a machine learning technique for building predictive models by creating an ensemble of weak learners and combining their predictions to create a stronger, more accurate model. The general idea of gradient boosting is to train a sequence of weak learners (e.g. decision trees) in a stage-wise manner, with each subsequent learner trying to correct the errors made by the previous learner. At each stage, the gradient boosting algorithm fits a new weak learner to the residual errors made by the previous learner. The residual errors are the difference between the true values and the predicted values of the target variable.
In gradient boosting, weights are assigned to the incorrectly classified samples in order to give more importance to the samples that are difficult to classify. This helps the weak learners in the ensemble to focus more on the samples that are most likely to improve the overall performance of the model.
The steps of the gradient boosting algorithm can be summarized in the following equations:
- Initialize the ensemble with a single weak learner, such as a decision tree, and make predictions using this learner:
prediction(1) = weak_learner_prediction(1)
- Calculate the residual errors between the true values and the predicted values of the target variable:
residual_error(t) = true_value(t) – prediction(t)
- Train a new weak learner to predict the residual errors from the previous step:
weak_learner_prediction(t+1) = train(weak_learner, residual_error(t))
- Update the predictions of the ensemble by adding the predictions of the new weak learner to the previous predictions:
prediction(t+1) = prediction(t) + weak_learner_prediction(t+1)
- Repeat steps 2-4 until the desired number of weak learners has been trained.
What is AdaBoost and what are the steps of the algorithm? Include equations.
AdaBoost works by weighting the observations in the training set and adjusting the weight of each observation at each iteration of the algorithm based on the performance of the previous models. The idea behind AdaBoost is to train a sequence of weak learners in an iterative manner, with each learner trying to correct the mistakes of the previous learner. The final model is a weighted average of all the weak models.
Here are the steps of the AdaBoost algorithm:
- Initialize the weights of the observations in the training set:
- At the beginning, all the observations in the training set are given the same weight.
- Train a weak learner:
- Train a weak learner (e.g., a decision tree) on the training set using the current weights of the observations (My note: sample with replacement).
- Calculate the error of the weak learner:
- Calculate the error (my note: total error) on the training set using the following equation:error = sum(weights[i] * I[prediction[i] != y[i]])
- Calculate the weight of the weak learner:
- Calculate the weight of the weak learner using the following equation :
alpha = 0.5 * log((1 – total error) / total error)
- Calculate the weight of the weak learner using the following equation :
- Adjust the weights of the observations:
- Adjust the weights of the observations using the following equation:
weights[i+1] = weights[i] * exp(-alpha * I[prediction[i] == y[i]])
- Adjust the weights of the observations using the following equation:
- Normalize the weights:
- Normalize the weights so that they sum up to 1.
- Repeat steps 2-6:
- Repeat steps 2-6 a predetermined number of times or until the error of the model becomes small enough.
- Return the final model:
- Return the final model as a weighted average of all the weak models.
My note:
Short note on exp(-alpha * I[prediction[i] == y[i]]) i.e. for misclassification
When the performance is relatively large the last stump did a good job in classifying the records now the new sample weight will be much larger than the old one. When the performance is relatively low the last stump did not do a good job in classifying the records now the new sample weight will only be little larger than the old one.
No misclassification: When the performance is relatively large the last stump did a good job in classifying the records now the new sample weight will be very small than the old one. When the performance is relatively small the last stump did not do a good job in classifying the records now the new sample weight will only be little smaller than the old one.
What is the difference between gradient boosting algorithm and adaptive boosting?
Gradient boosting and adaptive boosting are both ensemble learning algorithms that can be used to improve the performance of a weak learner (a model that performs only slightly better than random guessing) by combining the predictions of multiple weak learners.
The main difference between gradient boosting and adaptive boosting is the way in which the weak learners are trained and combined.
In gradient boosting, the weak learners are trained sequentially, with each learner trying to correct the mistakes of the previous learner. In adaptive boosting (also known as AdaBoost), the weak learners are also trained sequentially, but the training process is different. Each weak learner is trained on a different subset of the training data, and the weights of the training examples are adjusted after each learner is trained to give more weight to the examples that were misclassified. The final prediction is made by combining the predictions of all of the learners using a weighted sum, where the weight of each learner is determined by its accuracy on the training data.