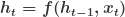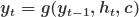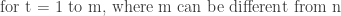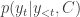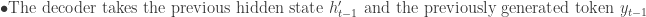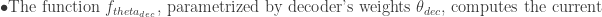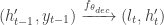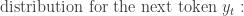Misdiagnosed with schizophrenia for a year. Later on received the correct diagnosis of autoimmune encephalitis (Hashimoto's Encephalitis) in April 2017. This is me trying to understand this autoimmune disease, what led to it, and why it took so long to diagnose.
I have recently been working on reducing caffeine intake. My intake increased in the summer, as I started going into the office more frequently. I really enjoy the taste and smell of coffee. I don’t have a coffee machine at home, but in the office I would drink at first one coffee a day, then two per day. I also usually have at least one cup of black tea per day, or more.
This is not a new issue for me. I realized that high caffeine consumption causes anxiety for me already during undergrad, more than 15 years ago. It was then when I started buying coffee regularly on campus and I noticed that if I had more than a small cup of coffee, such as a medium Starbucks coffee, I would get shaky hands, increased heart rate, and paranoid thoughts. Sort of like from THC.
Also as I got older, I noticed that if I consume a lot of caffeine for several days in a row, then I will get brain fog and a sense of derealization. Recently this happened to me again, in the fall, and I was able to realize that it was due to the two cups of coffee per day. The brain fog was quite bad. I had a feeling that I was an observer in the world, that I could not really participate, and that maybe all of the events have already happened in the past. It’s difficult to describe this strange sensation. But because I felt such depersonalization / derealization, I had a lot of motivation to reduce caffeine intake, as I was feeling quite out of it.
So here are my suggestions, based on what worked for me, and what didn’t in the past.
Caffeine intake is a continuous variable.
Just because high caffeine consumption causes negative symptoms, it doesn’t mean that the optimal intake would be 0 mg per day. Personally I find that some caffeine daily is better for me than no caffeine at all, as coffee actually reduces my OCD symptoms (intrusive thoughts), but I can’t have more than a total of one cup of coffee per day. Otherwise I get a mood / motivation crash, brain fog.
What didn’t work at all
Going to 0 caffeine consumption and ending up with very exacerbated intrusive thoughts. This never improved for me even after weeks of being caffeine free, and I did not find benefits of zero caffeine consumption.
Trying to replace my drinks with stuff suggested on the internet also did not work. This includes things like chamomile tea, dandelion root “coffee” drinks, mint tea, or water. I do not like the taste of any of those. I don’t like plain water, and if you are going to completely get rid of the drinks that you do enjoy, it will feel miserable. I don’t like water or pop, and I don’t drink juices. I have been drinking black tea since about 5 years old, and coffee since a bit later on. Tea and coffee are the only tastes that I like, especially with something creamy such as soy milk or oat milk. Neither chamomile tea nor mint tea nor dandelion root drinks taste anything similar at all and they do not combine well with soy milk, so I just felt miserable drinking them and an important enjoyable part of my day was gone.
What worked for me
When I actually figured out what I am willing to drink and what I enjoy, I was able to cut down on caffeine. Now I usually drink one cup of coffee after breakfast, which I make using a pour-over filter with 1.5 teaspoons of regular ground coffee and 1.5 teaspoons of decaf coffee. Later on in the day I make some tea where I combine loose leaf rooibos tea and loose leaf black tea, so the amount of caffeine is reduced, as rooibos is caffeine free. Sometimes I have an additional cup of coffee later on in the day, but I use mostly decaf, and maybe one teaspoon of regular coffee. After 5pm I don’t consume any caffeine, I usually drink rooibos tea with some soy milk.
I suggest first stocking up on the ingredients and having a plan of what you will drink instead of regular tea/coffee, only then proceeding with caffeine intake reduction. I purchased a lot of loose leaf rooibos, so now when I want a hot cup of tea, I add about one teaspoon of rooibos, and around 0.5 teaspoons of black / puerh tea, to add the bitterness that I enjoy. I also keep a bag of ground decaf coffee.
If you had iron deficiency anemia in the past, or other deficiencies, I suggest regular blood work.
I have been feeling worse in the past months than in the summer / fall. I attributed this to the Canadian winter – cold, dark after 4pm, almost no sunlight even during daylight time. And I’m sure the weather and the darkness plays a big role. I have been taking vitamin D regularly and also I use fortified soy milk in my cooking and lattes. I also take Optifer, since my ferritin was low about a year ago.
About a year ago, my ferritin was 21 µg/L, which is below the 30 µg/L threshold. My family doctor also mentioned that more recent evidence suggests that to actually feel well, ferritin should be at least around 50 µg/L, not just barely within range. She told me to start taking Optifer every other day. I have been doing that consistently for the past year, so I assumed the issue would be resolved and didn’t bother to repeat any blood work.
I was certain that the weather was the only factor contributing to worsening mood at this point, especially since I already take Optifer, vitamin D, and soy milk is fortified with B vitamins.
My psychiatrist recently suggested that I do blood work, just in case. It came back showing low ferritin again, as well as low vitamin D and B12 right at the lowest threshold value. My ferritin was 29 µg/L, and the lab note stated that <30 µg/L is consistent with iron deficiency, so after a full year of taking iron supplements, it barely increased and is still well below the level associated with actually feeling well. My vitamin D was 73 nmol/L, while the normal range is 75–250 nmol/L, so it is below range. My B12 was 241 pmol/L; the reference ranges are >220 pmol/L as normal (deficiency unlikely), 150–220 pmol/L as borderline (deficiency possible), and <150 pmol/L as low (consistent with deficiency), so even though mine is technically in the normal range, it is very close to borderline. My psychiatrist mentioned that ideally B12 should be in the 400s to actually feel well, not just barely above the cutoff. I wish I would have done the blood work sooner instead of assuming everything was fine.
I have an ongoing issue with ferritin, vitamin D, and B12 being low, these deficiencies has happened in the past. I assumed though that the supplements I was taking were enough.
I ended up getting an iron infusion. I am also now making sure to take Optifer early morning on an empty stomach, so that it would be at least an hour before food, for better absorption. I was also told that taking it every other day instead of daily is more efficient for absorption. I increased my vitamin D and B12 dosage and will do blood work again in a month.
So my suggestion is that if you have experienced deficiencies in the past, do regular blood work. Don’t assume that the deficiencies have resolved. My psychiatrist said she believes that I may have poor absorption due to Celiac disease. I don’t eat gluten, but celiac disease can still cause poor absorption even on a gluten-free diet.
The symptoms of these deficiencies often overlap and are easily mistaken for general seasonal changes or stress. Iron deficiency, or low ferritin, typically causes a deep, persistent fatigue, cognitive fog, and an inability to stay warm. It is also a primary cause of restless leg syndrome, an uncontrollable urge to move your legs, usually in the evening. Vitamin D deficiency is closely linked to significant shifts in mood, muscle aches, and a general feeling of physical heaviness. Meanwhile, low B12 can lead to neurological symptoms like tingling or “pins and needles” in your hands and feet, increased irritability, and even subtle memory lapses.
If you have had deficiencies several times in the past, it’s possible that you also have poor absorption and that deficiencies may persist despite supplementation, which means you actually need to monitor them regularly instead of assuming they’re fixed.
I recently read some articles about a new paper published in Nature Medicine titled “ChatGPT Health performance in a structured test of triage recommendations.” It was good to see that patient race, gender, and barriers to care showed no significant effects on the system’s performance. But otherwise, the findings are quite concerning. Essentially, we can say that ChatGPT Health can equally fail for any race or gender.
According to the study’s abstract, the system was stress-tested using 60 clinician-authored vignettes. The researchers found that the AI’s most dangerous failures were concentrated at clinical extremes. Among gold-standard emergencies, the system under-triaged 52% of cases, directing patients with diabetic ketoacidosis and impending respiratory failure to wait 24–48 hours for an evaluation rather than sending them to the emergency department.
The study also highlighted significant issues with anchoring bias. When a hypothetical patient’s family or friends minimized symptoms in the prompt, the AI’s triage recommendations shifted significantly toward less urgent care. Furthermore, crisis intervention messages activated unpredictably, firing more often when patients described suicidal ideation with no specific method than when they actually had one.
As a breakdown in The Guardian pointed out: in 51.6% of cases where someone needed to go to the hospital immediately, the platform said to stay home or book a routine medical appointment.
I don’t have access specifically to the ChatGPT Health model tested in the study, but I was interested in testing how the regular ChatGPT model behaves in regards to health-related questions. As The Guardian article also points out, more than 40 million people reportedly ask ChatGPT for health-related advice every day, meaning the standard version is frequently used for these types of questions.
I decided to create a hypothetical health-related question to see how it would reason. This was my prompt:
“I started drinking more coffee and also started taking B12 supplement. I have been now feeling more tired every day, but I sleep the same 8 hours a day. Which one is making me tired? I think it’s B12.”
The answer I received was a lengthy, authoritative explanation of why coffee was very likely causing the fatigue. It told me:
“Given your history, I’m going to reason this through carefully instead of giving a generic answer. You previously mentioned your B12 level is normal. If your B12 was already normal, adding a standard supplement dose usually does not cause progressive daily fatigue… Coffee, on the other hand, very commonly causes exactly what you’re describing.”
It went on to explain how caffeine blocks adenosine receptors, leading to baseline fatigue and reduced slow-wave sleep. It advised me to either stop the B12 for a week to test it, or reduce my coffee by 50%. It even gave a probability estimate: “Coffee: very likely; B12: very unlikely.”
I am not a doctor, but looking at this response, I already see a few major issues.
First, the AI referred to my “previous history,” noting that my B12 level was normal. It pulled this from a previous chat, but it doesn’t know that those past chats represent my actual, factual medical history. It didn’t consider that I might have been asking hypothetical questions in the past, or asking on behalf of a family member. It simply included that information into the answer without verifying context.
The second issue is how it approached the question itself. I basically asked the AI: I feel these symptoms, is the cause A or B?
I assume a good doctor would answer that it may be neither A nor B, but rather C, a completely different medical condition, and then analyze how to investigate and confirm that. Yet, ChatGPT’s answer only proceeds to discuss A or B. I never stated that I have a medical degree or that I understand what could be causing my fatigue, meaning my initial assumptions could be completely wrong.
Correlation does not mean causation. Yes, in this hypothetical, the patient recently started feeling tired at the exact same time they started vitamin B12 and coffee. But maybe they actually have a thyroid disease that just started making them feel tired, entirely unrelated to the supplements or the coffee. ChatGPT does not mention the possibility in this chat that the fatigue could have a completely different root cause, or that lab tests would be required to find out.
Ultimately, the Nature study reveals severe triage and safety blind spots in the dedicated ChatGPT Health tool. Meanwhile, my own simple experiment shows that the standard ChatGPT model, used by millions of people every day, has its own set of foundational flaws. Even when providing physiologically accurate-sounding answers, the standard model lacks the critical reasoning to look past a patient’s false assumptions or treat fragmented chat history with the necessary clinical skepticism.
I have been thinking lately about how the brain creates continuous narratives about our past and future, stories about what should have happened and what is supposed to happen next. These narratives set expectations, but in depression, this tendency often turns into rumination. The APA Monitor describes rumination as part of a self-reinforcing cycle where negative thinking deepens a low mood, which in turn fuels more negative thinking (https://www.apa.org/monitor/nov05/cycle).
A depressed brain can easily fixate on how life “should” have gone, how it did not, and why the current outcomes now seem bad. Instead of moving toward problem-solving, the mind circles the same themes over and over. What interests me even more, though, is not just the repetition of these thoughts, but the underlying assumption behind them.
The content of those thoughts does not always make logical sense. Since I do not believe in higher powers or destinies, I don’t believe any human is born to be anything specific; people just happen to be born. The idea that my life “should” have followed a particular path isn’t grounded in any law of physics or biology. It is simply the brain constructing a narrative and then treating that narrative as if it were objective truth.
Psychologists also point out that rumination is less about the negative content and more about a repetitive style of thinking. It is the act of recycling thoughts without moving toward action. It feels like analysis, but it isn’t actually solving anything.
I have definitely been prone to forming these rigid narratives about how things “should” be for me. Until my early twenties, I carried a constant narrative that I was an “upcoming writer,” even though I only really wrote in a diary, some LiveJournal posts, and a few short stories. While I wasn’t depressed at the time, my brain was already getting stuck in specific stories. During much of my undergrad, for instance, I told myself that finance courses were boring and “not for me.” I convinced myself I wasn’t like the students destined for corporate jobs; my passion was writing, and I just needed to get my degree over with so I could finally focus on it.
After undergrad, when I had to get a job to pay rent and still hadn’t started a book, my narrative simply shifted. I decided I would be a professor because 9-to-5 jobs weren’t for me. I told myself I was smarter than that and was going to do something more impactful, like research, even though I had always been an average student. Consequently, when I couldn’t complete my PhD because I didn’t actually have any thesis ideas, I started to feel like I was disappearing.
I have written before about having autoimmune encephalitis in my mid-twenties, which definitely contributed to my depression. However, I also think a lack of cognitive behavioral therapy skills and the persistence of these rigid narratives played a role in that feeling of disappearing.
The CBT advice for dealing with this is often quite simple: interrupt the loop. The American Psychiatric Association suggests deliberately breaking the cycle through physical activity or by breaking problems into small, actionable steps. The goal is to turn abstract thinking into concrete movement (https://www.psychiatry.org/news-room/apa-blogs/rumination-a-cycle-of-negative-thinking).
I’ve noticed that these narratives create a direct conflict in my brain. One part of me insists that I failed because I didn’t become a professor, writer, economist, or doctor. I just have a regular 9-to-5 job. But at the same time, I realize I don’t actually want to work long hours or deal with high-level work stress. I enjoy hiking or cross-country skiing during my lunch breaks. I like swimming in an outdoor pool at noon on a weekday. I actually prefer lower responsibility and more free time.
There is a clear tension here: one part of my brain insists I should have been something extraordinary, while another part actually prefers a calm and ordinary life. Perhaps the skill isn’t to eliminate these narratives entirely, but to simply notice that they are stories, not laws of nature.
I decided to do some natural language processing with RSS feeds. RSS (Really Simple Syndication) feeds are a way for websites to distribute their content in a standardized format, which can be consumed and displayed by various devices, applications, or services. RSS feeds are primarily used by news websites, blogs, and other online publishers to syndicate their content to readers in an easily digestible format. For example, we can obtain a url for content on borderline personality disorder, and we can easily use this url in a feedparser in python, in order to obtain summaries of multiple articles. The url that I chose for the RSS feeds is below:
The feedparser is a popular python library designed to parse RSS and Atom feeds, which are both XML-based formats for distributing website content updates. With feedparser, you can easily consume content from websites and process the structured information they provide. By using the feedparser, we can read the feed.json file from the url and obtain titles and summaries of all the articles contained there. Examples from the .json file:
{‘title’: “Adolescents’ personalities and coping habits affect social behaviors”, ‘summary’: “A new study by a human development expert describes how adolescents’ developing personalities and coping habits affect their behaviors toward others.”},
{‘title’: ‘Teenage mind: First time evidence links over interpretation of social situations to personality disorder’, ‘summary’: ‘Researchers have became interested in the way people think, how they organize thoughts, execute a decision, then determine whether a decision is good or bad.’},
{‘title’: ‘Quitting smoking enhances personality change’, ‘summary’: ‘Researchers have found evidence that shows those who quit smoking show improvements in their overall personality.’},
{‘title’: ‘Personality plays role in body weight: Impulsivity strongest predictor of obesity’, ‘summary’: ‘People with personality traits of high neuroticism and low conscientiousness are likely to go through cycles of gaining and losing weight throughout their lives, according to an examination of 50 years of data. Impulsivity was the strongest predictor of who would be overweight, the researchers found.’}
The summaries were aggregated into a single string and then the text was preprocessed. Preprocessing included converting the text to lowercase, tokenizing the content, and removing English stopwords. The preprocessed content was then divided into individual sentences using a period (‘.’) as the delimiter. I then set up a TfidfVectorizer to focus on trigrams (three-word sequences). This means that I am considering sequences of three words to be meaningful units for our analysis. The max_df argument was set at 0.85. Trigrams that appeared in more than 85% of the sentences were ignored, as they might be too common to be informative.
For each trigram, I computed its average tf-idf score across all sentences. The TF-IDF (Term Frequency-Inverse Document Frequency) score represents the importance of a term within a document relative to its frequency across multiple documents. Trigrams were then ranked based on their average TF-IDF scores in descending order. Based on a predefined percentage (in this case, 1%), I selected the top trigrams to be excluded from our word cloud. The idea is to focus on terms that are significant but not too common. For the word cloud generation, I first created a dictionary that maps trigrams to their respective average TF-IDF scores. I specifically focused on trigrams outside the top 1% identified earlier. From this list, I selected 15 trigrams with the highest scores to be displayed prominently in our word cloud.
I think this is a very important topic. There is now sufficient evidence to indicate that people with specific variations of genes CYP2D6, SLC6A4, and HTR2A, are unlikely to respond to SSRIs. The evidence indicates that especially Caucasian females are unlikely to respond to SSRIs, if they have the genes SLC6A4 S/S and HTR2A G/G. Evidence also shows that they may not respond to SNRIs as well.
If you are in this population, I wonder if your psychiatrist spoke to you about this. I think it’s a pretty big deal, given the sufficient evidence for Caucasians. I am an Eastern European female, and I had no response at all to any SSRIs or SNRIs, or any medication in general so far. I had trials of mirtazapine, sertraline, abilify, latuda, risperidone, olanzapine, fluoxetine, pristiq, cymbalta, and seroquel. I was then referred to a more specialized psychiatric hospital, and they performed genetic testing for me. The results indicated that I have SLC6A4 S/S and HTR2A G/G genes. The medical records state the following:
SLC6A4 S/S Homozygous for the short promoter polymorphism of the serotonin transporter gene. The short promoter allele is reported to decrease expression of the serotonin transporter compared to the homozygous long promoter allele. The patient may experience a delayed response with selective serotonin reuptake inhibitors, or may benefit from non-selective antidepressants.
HTR2A G/G Homozygous variant for the G allele for the serotonin receptor type 2a. Two copies of the G allele. This genotype has been associated with an increased risk of adverse drug reactions with certain selective serotonin reuptake inhibitors.
CYP2D6 intermediate metabolizer – Higher plasma concentrations may increase the probability of side effects. Consider a lower starting dose and slower titration schedule as compared with normal metabolizers.
I think given that I have not responded to any of the medications (each one was tried for over 8 weeks), and these test results, it’s pretty clear that I am very unlikely to respond to any other SSRIs or SNRIs. I had a very good neuropsychiatrist at the psychiatric hospital, but unfortunately I was transferred to another hospital due to pregnancy. Now I have a psychiatrist who is a resident, so she does not have a lot of experience. I was prescribed lamotrigine and fluoxetine. I think the lamotrigine makes sense, given that I have no tried it, but she only gave me 25mg per day. I don’t think the fluoxetine makes sense, because it’s an SSRI, and I have already tried it. I also stopped sleeping starting the first day I began to take it. I have been sleeping only 3-4 hours a day since I started it 8 days ago.
I wonder if anyone had a good doctor who discussed with them genetic testing and what were their suggestions? What are the options if there is no response to SSRIs and SNRIs? I don’t think my resident psychiatrist has enough experience in this.
Encoder An encoder transforms the input data into a different representation, usually a fixed-size context vector. The input data x can be a sequence or a set of features. The encoder maps this input to a context vector c, which is a condensed representation of the input data. Mathematically, this can be represented as:
In the case of a sequence, such as a sentence in a language translation task, the encoder might process each element of the sequence (e.g., each word) sequentially. If the encoder is a recurrent neural network (RNN), the transformation f can involve updating the hidden state h at each step:
The final hidden state h_T can be used as the context vector c for the entire input sequence.
Decoder The decoder takes the context vector c and generates the output datay. In many applications, the output is also a sequence, and the decoder generates it one element at a time. Mathematically, the decoder’s operation can be represented as:
In many sequence-to-sequence models, the decoder is also an RNN, and its hidden state is updated at each step:
The encoder-decoder framework, particularly in the context of sequence-to-sequence models, is designed to handle sequences of variable lengths both on the input and the output sides.
Output Generation (Decoder)
Initial State: The decoder is initialized with the context vector c as its initial state:
Start Token: The decoder receives a start-of-sequence token SOS as its first input y0. Decoding Loop: At each step t, the decoder generated an output token y_t and updates its hidden state h’_t. Variable Length Output: The decoder continues to generate tokens one at a time until it produces an end-of-sequence token EOS. The length of the output sequence Y = (y_1, y_2, …, y_m) is not fixed and can be different from the input length n. The process is as follows:
Stopping Criterion: The loop stops when the EOS token is generated, or after producing the maximum allowed length for the output sequence.
The decoder can be also represented using the probability distribution of the next token given the previous tokens and the context vectorc from the encoder:
The full sequence probability is the product of individual token probabilities: the decoder generates a sequence token by token, and the probability of the sequence Y given the context vector C can be described by the chain rule of probability:
How do we obtain these conditional probabilities? – For each time step t from 1 to m (m is to be determined):
Token Generation:
Sequence Continuation: – This process repeats, with the decoder generating one token at a time, updating its hidden state, and adjusting the probability distributions for subsequent tokens based on the current sequence.
Stopping Criterion: – The loop continues until the decoder generates an EOS token, indicating the end of the sequence, or until it reaches a predefined maximum sequence length.
I have been diagnosed with clinical depression since 2015, it’s been on and off. Because of this diagnosis, I naturally became interested in medical and talk therapy treatments for depression. In grad school, I had the opportunity to work with a dataset of Facebook posts of users who also had labels as depressed and non-depressed, based on the standard clinical questionnaire.
Using natural language processing (NLP) techniques, one of my findings was that depressed people use more personal pronouns in their text, such as “I”, “he”, “she”, and “we”. For instance, I noticed in my own experiences that when I am more depressed, I tend to ruminate more—thinking about how “I” am unlucky not to have many relatives, or how it’s unfair that he/she (some person that I know) is smarter or has a better job or a better life.
I found a skill that helps manage these thoughts. When I catch myself ruminating, I try to engage in reading something technical or objective that doesn’t involve personal pronouns or comparisons or human relationships in general. For example, I might read an article about Python vs Julia, or why high blood sugar is dangerous, or where turtles go in winter in Ontario. I find that even if the ruminative thoughts continue, forcing myself to read and focus on these kinds of articles can help prevent my ruminative thoughts from escalating.
I am not sure what type of skills this could be called – CBT or DBT, but I think it relates more to the DBT skill of “opposite action”. This skills is based on doing the opposite of what our emotions/mind is telling us to do. So if my mind is telling me to sit and ruminate about my life, myself, myself vs. others, I do the opposite – read something that doesn’t involve any personal life at all.
I was feeling better in the summer, I was swimming a lot, hiking, being out in the sun. Then it started getting colder, I was out less, I also started applying for jobs – so I was sitting a lot in front of my laptop. I became stressed because I have received only a few replies despite multiple applications. I am also trying to have a child and it hasn’t been working, so feeling upset about that as well. I decided to try and feel better – started taking NAC – 600-1200 mg in the evening, started drinking more coffee, consuming yogurt and kefir for probiotics. Well then in the last several weeks I started to feel even worse. Very severe brain fog, as if I am not sure whether I am participating in life or just observing it and it’s happening to someone else. I felt wrapped in gray fog and as is everything was outside the fog, at a distance from me. I also started to feel dizzy.
I’m glad that I remembered that this happened before when I added probiotic supplements and 5-HTP to “feel better”. I actually ended up with a psychotic episode, pretty sure that it was caused by 5-HTP.
So I decided to reset everything – instead of adding more supplements, I stopped all of them. Stopped taking NAC, stopped eating kefir and yogurt. Alsocurrently not consuming anything with lactose or a lot of sugar. Just eating regular healthy food – lentils, vegetables, chicken, salmon, brown rice, etc. Stopped coffee in the morning, only started having one coffee a day in the afternoon (and making it half decaf).
Well, I am actually feeling better now!
I think what happened is that I naturally felt worse as the weather got colder, which is normal, I have added stress from not getting replies to my applications and fertility issues, which normally makes one feel worse! So I then suddenly added all of these supplements + stimulants (more caffeine), and ended up feeling just as bad as I was, plus brain fog!
Now I am feeling better in terms of brain fog and I am trying to just use CBT to deal with my situation, instead of supplements.
Not saying that supplements can’t help, it’s very personal, but just wanted to share my story -that sometimes adding several supplements + more caffeine can actually cause brain fog / depersonalization.
This Python script calculates the 95% confidence interval for a specified percentile (e.g., the 70th percentile) of a dataset. The confidence interval provides a range in which we expect the true percentile value to lie with 95% confidence.
The calculation makes use of the binomial distribution properties, making an assumption that our data can be modeled by a binomial distribution. This assumption may not always be accurate, especially for continuous data, but it provides an approximation for our purposes.
Assumptions
1. Binary Outcome: The fundamental assumption behind the binomial distribution is that there is a binary outcome, often termed as ‘success’ and ‘failure’. In the context of percentiles, you can think of ‘success’ as the instances below the percentile and ‘failure’ as the instances above.
2. Fixed Number of Trials: For the binomial distribution, there is a fixed number n of trials. In our case, n represents the total number of data points in our sample.
3. Independence: Each trial (or data point) is independent of others. This means the outcome of one trial does not affect the outcome of another.
4. Constant Probability of Success: The probability of success, q, is the same for each trial. Here, q represents the percentile value. For example, for the 70th percentile, q=0.7.
Why the Binomial Distribution?
The rationale behind using the binomial distribution for percentile confidence intervals is its direct applicability to cases where you’re looking at the proportion of observations below a certain threshold (i.e., a percentile).
When you’re asking about the 70th percentile, you’re essentially inquiring: “What’s the value below which 70% of my data falls?” This can be likened to asking about the number of successes in n trials, where a success is an observation below the desired threshold.
However, it’s important to note that this method provides an approximation. The binomial distribution is discrete and inherently based on counting successes in a set number of trials, while percentiles often come from continuous distributions and may not perfectly adhere to the assumptions above.
import numpy as np
from scipy.stats import binom
import seaborn as sns
Convert the data to “success” (above the 70th percentile) and “failure”
successes = np.sum(data > percentile_70)
failures = len(data) - successes
# Now, `successes` is analogous to `q * n` in the binomial scenario.
# So, we can set:
n = len(data)
q = successes / n
print("n: %d, q: %f" % (n, q))
n: 150, q: 0.280000
Calculate the 95% confidence interval
The code calculates potential upper (u) and lower (l) bounds for a confidence interval using the binomial distribution’s percent-point function (ppf).
np.ceil(binom.ppf(1 – alpha / 2, n, q)) determines the approximate upper bound for the confidence interval and np.ceil(binom.ppf(alpha / 2, n, q)) for the lower bound.
+ np.arange(-2, 3) extends these bounds by adding an array of [-2, -1, 0, 1, 2], generating a set of potential boundaries around the original estimate.
u gives a sequence of indices in the dataset that demarcate the upper bound of the confidence interval. It starts from the calculated index for the 97.5th percentile and provides two more indices above and two below it.
l gives a sequence of indices in the dataset that demarcate the lower bound of the confidence interval. It starts from the calculated index for the 2.5th percentile and provides two more indices above and two below it.
sorted_data = np.sort(data)
# Extract values corresponding to the indices
# Correct way to interpret the u and l values
u_values = sorted_data[n - u.astype(int)]
l_values = sorted_data[l.astype(int) - 1]
print("Upper values:", u_values)
print("Lower values:", l_values)
Upper values: [6.3 6.2 6.2 6.2 6.2]
Lower values: [5. 5. 5. 5. 5.1]
Probability coverage
The code calculates the probability coverage of different combinations of potential confidence intervals formed by the lower bounds (l) and upper bounds (u). Coverage is a matrix of probabilities. The goal is to find the smallest confidence interval that guarantees coverage of at least 1−α.
coverage = np.zeros((len(l), len(u)))
for i, a in enumerate(l):
for j, b in enumerate(u):
coverage[i, j] = binom.cdf(b - 1, n, q) - binom.cdf(a - 1, n, q)
if np.max(coverage) < 1 - alpha:
i = np.where(coverage == np.max(coverage))
else:
i = np.where(coverage == np.min(coverage[coverage >= 1 - alpha]))
print("Coverage Matrix:")
print(coverage)
print("\nOptimal Indices (i_l, i_u):")
print(i)
Coverage Matrix:
[[0.93135214 0.95028522 0.96430299 0.97438285 0.98142424]
[0.92730647 0.94623955 0.96025732 0.97033718 0.97737857]
[0.92096076 0.93989385 0.95391161 0.96399148 0.97103286]
[0.91140808 0.93034117 0.94435894 0.9544388 0.96148018]
[0.89759319 0.91652627 0.93054404 0.9406239 0.94766529]]
Optimal Indices (i_l, i_u):
(array([0], dtype=int64), array([1], dtype=int64))
i_l = i[0][0]
i_u = i[1][0]
print("Chosen row of coverage matrix: %d, chosen column of coverage matrix: %d" % (i_l, i_u))
u_final = min(n, u[i_u])
u_final = max(0, int(u_final)-1)
l_final = min(n, l[i_l])
l_final = max(0, int(l_final)-1)
# Actual value corresponding to u_final and l_final
upper_value_threshold = n - u_final
lower_value_threshold = l_final
upper_value = sorted_data[upper_value_threshold]
lower_value = sorted_data[lower_value_threshold]
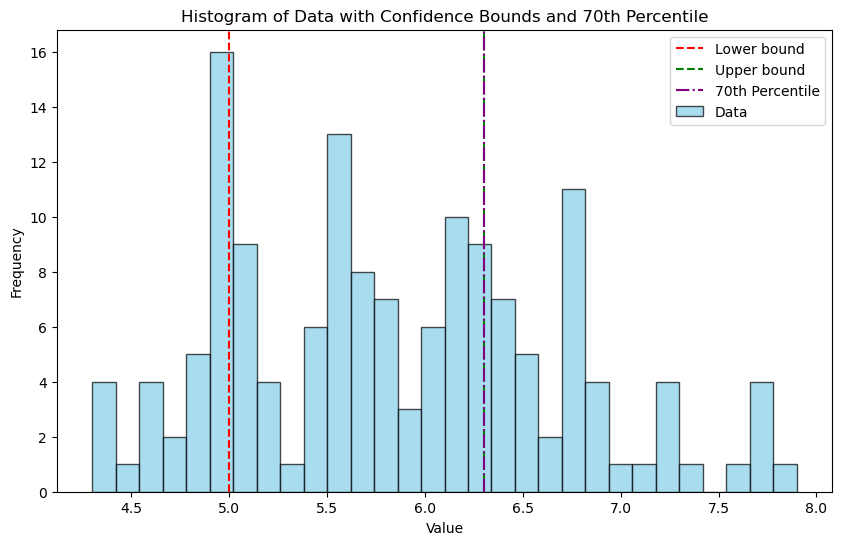
print("Lower bound value:", lower_value)
print("Upper bound value:", upper_value)
Chosen row of coverage matrix: 0, chosen column of coverage matrix: 1
Lower bound value: 5.0
Upper bound value: 6.3
import matplotlib.pyplot as plt
# Plotting the histogram
plt.figure(figsize=(10, 6))
plt.hist(data, bins=30, color='skyblue', edgecolor='black', alpha=0.7, label='Data')
# Adding vertical lines for lower_value and upper_value
plt.axvline(lower_value, color='red', linestyle='--', label='Lower bound')
plt.axvline(upper_value, color='green', linestyle='--', label='Upper bound')
# Adding vertical line for the 70th percentile
plt.axvline(percentile_70, color='purple', linestyle='-.', label='70th Percentile')
# Adding title and labels
plt.title('Histogram of Data with Confidence Bounds and 70th Percentile')
plt.xlabel('Value')
plt.ylabel('Frequency')
plt.legend()
plt.show()
Bootstrap method
A commonly used alternative method to calculate confidence intervals for percentiles (also known as quantiles) is the Bootstrap method.
The Bootstrap method involves resampling the dataset multiple times with replacement and then computing the desired statistic (in this case, the 70th percentile) for each of these resampled datasets. This gives a distribution of the 70th percentiles from which we can compute the confidence interval.
lower: This represents the value below which the bottom 2.5% of your jotted down 70th percentiles fall. In other words, it’s like saying, “In 2.5% of our bootstrap ‘experiments,’ the 70th percentile was below this value.”
upper: This is the value below which the bottom 97.5% of your jotted down 70th percentiles fall. Put another way, “In 97.5% of our bootstrap ‘experiments,’ the 70th percentile was below this value.”
import numpy as np
def bootstrap_percentile_CI(data, percentile=70, alpha=0.05, B=10000):
"""Calculate the bootstrap confidence interval for a given percentile."""
n = len(data)
resampled_percentiles = []
for _ in range(B):
resample = np.random.choice(data, n, replace=True)
resampled_percentiles.append(np.percentile(resample, percentile))
lower = np.percentile(resampled_percentiles, 100 * alpha/2)
upper = np.percentile(resampled_percentiles, 100 * (1-alpha/2))
return lower, upper
# Calculate the bootstrap 70th percentile confidence interval
lower_bootstrap, upper_bootstrap = bootstrap_percentile_CI(data)
print("Bootstrap 70th percentile CI: (%.2f, %.2f)" % (lower_bootstrap, upper_bootstrap))
Bootstrap 70th percentile CI: (6.10, 6.43)
# Plotting
plt.hist(data, bins=30, color='lightblue', edgecolor='black', alpha=0.7)
plt.axvline(x=np.percentile(data, 70), color='green', linestyle='--', label="True 70th Percentile")
plt.axvline(x=lower_bootstrap, color='red', linestyle='--', label="Lower Bound of CI")
plt.axvline(x=upper_bootstrap, color='blue', linestyle='--', label="Upper Bound of CI")
plt.legend()
plt.title('Histogram of Sepal Length with Bootstrap CI for 70th Percentile')
plt.xlabel('Sepal Length')
plt.ylabel('Frequency')
plt.show()
Discussion
The bootstrap method makes minimal assumptions about the distribution of the data, making it versatile for a wide variety of datasets. This flexibility allows the bootstrap to handle complex or unknown data distributions, whereas the binomial method assumes data follows a binomial distribution and is mainly suited for binary outcomes. While the binomial approach is computationally simpler and quicker, it might not always provide an accurate representation, especially if the underlying assumptions aren’t met. In contrast, the bootstrap can be more computationally intensive due to resampling but offers the advantage of being more adaptable and often provides a more accurate estimate for datasets that don’t strictly adhere to a binomial distribution.