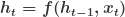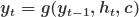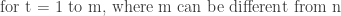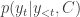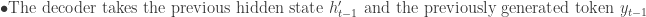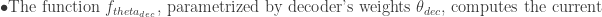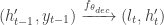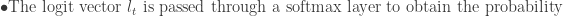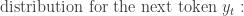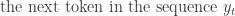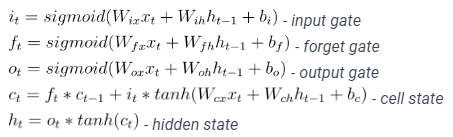Encoder An encoder transforms the input data into a different representation, usually a fixed-size context vector. The input data x can be a sequence or a set of features. The encoder maps this input to a context vector c, which is a condensed representation of the input data. Mathematically, this can be represented as:
In the case of a sequence, such as a sentence in a language translation task, the encoder might process each element of the sequence (e.g., each word) sequentially. If the encoder is a recurrent neural network (RNN), the transformation f can involve updating the hidden state h at each step:
The final hidden state h_T can be used as the context vector c for the entire input sequence.
Decoder The decoder takes the context vector c and generates the output datay. In many applications, the output is also a sequence, and the decoder generates it one element at a time. Mathematically, the decoder’s operation can be represented as:
In many sequence-to-sequence models, the decoder is also an RNN, and its hidden state is updated at each step:
The encoder-decoder framework, particularly in the context of sequence-to-sequence models, is designed to handle sequences of variable lengths both on the input and the output sides.
Output Generation (Decoder)
Initial State: The decoder is initialized with the context vector c as its initial state:
Start Token: The decoder receives a start-of-sequence token SOS as its first input y0. Decoding Loop: At each step t, the decoder generated an output token y_t and updates its hidden state h’_t. Variable Length Output: The decoder continues to generate tokens one at a time until it produces an end-of-sequence token EOS. The length of the output sequence Y = (y_1, y_2, …, y_m) is not fixed and can be different from the input length n. The process is as follows:
Stopping Criterion: The loop stops when the EOS token is generated, or after producing the maximum allowed length for the output sequence.
The decoder can be also represented using the probability distribution of the next token given the previous tokens and the context vectorc from the encoder:
The full sequence probability is the product of individual token probabilities: the decoder generates a sequence token by token, and the probability of the sequence Y given the context vector C can be described by the chain rule of probability:
How do we obtain these conditional probabilities? – For each time step t from 1 to m (m is to be determined):
Token Generation:
Sequence Continuation: – This process repeats, with the decoder generating one token at a time, updating its hidden state, and adjusting the probability distributions for subsequent tokens based on the current sequence.
Stopping Criterion: – The loop continues until the decoder generates an EOS token, indicating the end of the sequence, or until it reaches a predefined maximum sequence length.
Sequence-to-Sequence (Seq2Seq) models are a type of neural network architecture used for natural language processing tasks, such as machine translation, text summarization, and conversational modeling. The basic idea behind Seq2Seq models is to map a variable-length input sequence to a variable-length output sequence.
Seq2Seq models consist of two parts: an encoder and a decoder. The encoder takes an input sequence, such as a sentence, and generates a fixed-length representation of it, called the context vector. The decoder then takes the context vector as input and generates the output sequence, such as a translation of the input sentence into another language. Both encoder and decoder contain multiple recurrent units that take one element as input. The encoder processes the input sequence one word at a time and generates a hidden stateh_i for each timestep i. Finally, it passes the last hidden state h_n to the decoder, which uses it as the initial state to generate the output sequence.
In a Seq2Seq model, the hidden state refers to the internal representation of the input sequence that is generated by the recurrent units in the encoder or decoder. The hidden state is a vector of numbers that represents the “memory” of the recurrent unit at each timestep.
Let’s consider a simple recurrent unit, such as the Long Short-Term Memory (LSTM) cell. An LSTM cell takes as input the current input vector x_t and the previous hidden state h_{t-1}, and produces the current hidden state h_t as output. The LSTM cell can be represented mathematically as follows:
Here, W_{ix}, W_{ih}, W_{fx}, W_{fh}, W_{ox}, W_{oh}, W_{cx}, and W_{ch} are weight matrices, b_i, b_f, b_o, and b_c are bias vectors, sigmoid is the sigmoid activation function, and tanh is the hyperbolic tangent activation function.
At each timestep t, the LSTM cell computes the input gate i_t, forget gate f_t, output gate o_t, and cell state c_t based on the current input x_t and the previous hidden state h_{t-1}. The current hidden state h_t is then computed based on the current cell state c_t and the output gate o_t. In this way, the hidden state h_t represents the internal memory of the LSTM cell at each timestep t. It contains information about the current input x_t as well as the previous inputs and hidden states, which allows the LSTM cell to maintain a “memory” of the input sequence as it is processed by the encoder or decoder.
Encoder and decoder
The Seq2Seq model consists of two parts: an encoder and a decoder. Both of these parts contain multiple recurrent units that take one element as input. The encoder processes the input sequence one word at a time and generates a hidden state h_i for each timestep i. Finally, it passes the last hidden state h_n to the decoder, which uses it as the initial state to generate the output sequence.
The final hidden state of the encoder represents the entire input sequence as a fixed-length vector. This fixed-length vector serves as a summary of the input sequence and is passed on to the decoder to generate the output sequence. The purpose of this fixed-length vector is to capture all the relevant information about the input sequence in a condensed form that can be easily used by the decoder. By encoding the input sequence into a fixed-length vector, the Seq2Seq model can handle input sequences of variable length and generate output sequences of variable length.
The decoder takes the fixed-length vector representation of the input sequence, called the context vector, and uses it as the initial hidden state s_0 to generate the output sequence. At each timestep t, the decoder produces an output y_t and an updated hidden state s_t based on the previous output and hidden state. This can be represented mathematically using linear algebra as follows:
Here, W_s, U_s, and V_s are weight matrices, b_s is a bias vector, c is the context vector (from the encoder), and f and g are activation functions. The decoder uses the previous output y_{t-1} and hidden state s_{t-1} as input to compute the updated hidden state s_t, which depends on the current input and the context vector. The updated hidden state s_t is then used to compute the current output y_t, which depends on the updated hidden state s_t. By iteratively updating the hidden state and producing outputs at each timestep, the decoder can generate a sequence of outputs that is conditioned on the input sequence and the context vector.
What is the context vector, where does it come from?
In a Seq2Seq model, the context vector is a fixed-length vector representation of the input sequence that is used by the decoder to generate the output sequence. The context vector is computed by the encoder and is passed on to the decoder as the final hidden state of the encoder.
What is a transformer? How is are decoders encoders used in transformers?
The Transformer architecture consists of an encoder and a decoder, similar to the Seq2Seq model. However, unlike the Seq2Seq model, the Transformer does not use recurrent neural networks (RNNs) to process the input sequence. Instead, it uses a self-attention mechanism that allows the model to attend to different parts of the input sequence at each layer.
In the Transformer architecture, both the encoder and the decoder are composed of multiple layers of self-attention and feedforward neural networks. The encoder takes the input sequence as input and generates a sequence of hidden representations, while the decoder takes the output sequence as input and generates a sequence of hidden representations that are conditioned on the input sequence and previous outputs.
Traditional Seq2Seq vs. attention-based models
In traditional Seq2Seq models, the encoder compresses the input sequence into a single fixed-length vector, which is then used as the initial hidden state of the decoder. However, in some more recent Seq2Seq models, such as the attention-based models, the encoder computes a context vector c_i for each output timestep i, which summarizes the relevant information from the input sequence that is needed for generating the output at that timestep.
The decoder then uses the context vector c_i along with the previous hidden state s_i-1 to generate the output for the current timestep i. This allows the decoder to focus on different parts of the input sequence at different timesteps and generate more accurate and informative outputs.
The context vector c_i is computed by taking a weighted sum of the encoder’s hidden states, where the weights are learned during training based on the decoder’s current state and the input sequence. This means that the context vector c_i is different for each output timestep i, allowing the decoder to attend to different parts of the input sequence as needed. The context vector c_i can be expressed mathematically as:
where i is the current timestep of the decoder and j indexes the hidden states of the encoder. The attention weights α_ij are calculated using an alignment model, which is typically a feedforward neural network (FFNN) parametrized by learnable weights. The alignment model takes as input the previous hidden state s_i-1 of the decoder and the current hidden state h_j of the encoder, and produces a scalar score e_ij:
where a is the alignment model. The scores are then normalized using the softmax function to obtain the attention weights α_ij:
where k indexes the hidden states of the encoder.
The attention weights α_ij reflect the importance of each hidden state h_i with respect to the previous hidden state s_i-1 in generating the output y_i. The higher the attention weight α_ij, the more important the corresponding hidden state h_i is for generating the output at the current timestep i. By computing a context vector c_i as a weighted sum of the encoder’s hidden states, the decoder is able to attend to different parts of the input sequence at different timesteps and generate more accurate and informative outputs.
The difference between context vector in Seq2Seq and context vector in attention
In a traditional Seq2Seq model, the encoder compresses the input sequence into a fixed-length vector, which is then used as the initial hidden state of the decoder. The decoder then generates the output sequence word by word, conditioned on the input and the previous output words. The fixed-length vector essentially contains all the information of the input sequence, and the decoder needs to rely solely on it to generate the output sequence. This can be expressed mathematically as:
c = h_n
where c is the fixed-length vector representing the input sequence, and h_n is the final hidden state of the encoder.
In an attention-based Seq2Seq model, the encoder computes a context vector c for each output timestep i, which summarizes the relevant information from the input sequence that is needed for generating the output at that timestep. The context vector is a weighted sum of the encoder’s hidden states, where the weights are learned during training based on the decoder’s current state and the input sequence.
The attention mechanism allows the decoder to choose which aspects of the input sequence to give attention to, rather than requiring the encoder to compress all the information into a single vector and transferring it to the decoder.
ELMo (Embeddings from Language Models) is a deep learning approach for representing words as vectors (also called word embeddings). It was developed by researchers at Allen Institute for Artificial Intelligence and introduced in a paper published in 2018.
ELMo represents words as contextualized embeddings, meaning that the embedding for a word can change based on the context in which it is used. For example, the word “bank” could have different embeddings depending on whether it is used to refer to a financial institution or the edge of a river.
ELMo has been shown to improve the performance of a variety of natural language processing tasks, including language translation, question answering, and text classification. It has become a popular approach for representing words in NLP models, and the trained ELMo embeddings are freely available for researchers to use.
How does ELMo differ from Word2Vec or GloVe?
ELMo (Embeddings from Language Models) is a deep learning approach for representing words as vectors (also called word embeddings). It differs from other word embedding approaches, such as Word2Vec and GloVe, in several key ways:
Contextualized embeddings: ELMo represents words as contextualized embeddings, meaning that the embedding for a word can change based on the context in which it is used. In contrast, Word2Vec and GloVe represent words as static embeddings, which do not take into account the context in which the word is used.
Deep learning approach: ELMo uses a deep learning model, specifically a bidirectional language model, to generate word embeddings. Word2Vec and GloVe, on the other hand, use more traditional machine learning approaches based on a neural network (Word2Vec) and matrix factorization (GloVe).
To generate context-dependent embeddings, ELMo uses a bi-directional Long Short-Term Memory (LSTM) network trained on a specific task (such as language modeling or machine translation). The LSTM processes the input sentence in both directions (left to right and right to left) and generates an embedding for each word based on its context in the sentence.
Overall, ELMo is a newer approach for representing words as vectors that has been shown to improve the performance of a variety of natural language processing tasks. It has become a popular choice for representing words in NLP models.
What is the model for training ELMo word embeddings?
The model used to train ELMo word embeddings is a bidirectional language model, which is a type of neural network that is trained to predict the next word in a sentence given the context of the words that come before and after it. To train the ELMo model, researchers at Allen Institute for Artificial Intelligence used a large dataset of text, such as news articles, books, and websites. The model was trained to predict the next word in a sentence given the context of the words that come before and after it. During training, the model learns to represent words as vectors (also called word embeddings) that capture the meaning of the word in the context of the sentence.
Explain in details the bidirectional language model
A bidirectional language model is a type of neural network that is trained to predict the next word in a sentence given the context of the words that come before and after it. It is called a “bidirectional” model because it takes into account the context of words on both sides of the word being predicted.
To understand how a bidirectional language model works, it is helpful to first understand how a unidirectional language model works. A unidirectional language model is a type of neural network that is trained to predict the next word in a sentence given the context of the words that come before it.
A unidirectional language model can be represented by the following equation:
This equation says that the probability of a word w[t] at time t (where time is the position of the word in the sentence) is determined by a function f of the words that come before it (w[t-1], w[t-2], …, w[1]). The function f is learned by the model during training.
A bidirectional language model extends this equation by also taking into account the context of the words that come after the word being predicted:
This equation says that the probability of a word w[t] at time t is determined by a function f of the words that come before it and the words that come after it. The function f is learned by the model during training.
In practice, a bidirectional language model is implemented as a neural network with two layers: a forward layer that processes the input words from left to right (w[1], w[2], …, w[t-1]), and a backward layer that processes the input words from right to left (w[n], w[n-1], …, w[t+1]). The output of these two layers is then combined and used to predict the next word in the sentence (w[t]). The forward and backward layers are typically implemented as recurrent neural networks (RNNs) or long short-term memory (LSTM) networks, which are neural networks that are designed to process sequences of data.
During training, the bidirectional language model is fed a sequence of words and is trained to predict the next word in the sequence. The model uses the output of the forward and backward layers to generate a prediction, and this prediction is compared to the actual next word in the sequence. The model’s weights are then updated to minimize the difference between the prediction and the actual word, and this process is repeated for each word in the training dataset. After training, the bidirectional language model can be used to generate word embeddings by extracting the output of the forward and backward layers for each word in the input sequence.
ELMo model training algorithm
Initialize the word vectors:
The word vectors are usually initialized randomly using a Gaussian distribution.
Alternatively, you can use pre-trained word vectors such as Word2Vec or GloVe.
Process the input sequence:
Input the sequence of words w[1], w[2], ..., w[t-1] into the forward layer and the backward layer.
The forward layer processes the words from left to right, and the backward layer processes the words from right to left.
Each layer has its own set of weights and biases, which are updated during training.
Compute the output:
The output of the forward layer and the backward layer are combined to form the final output o[t].
The final output is used to predict the next word w[t].
Compute the loss:
The loss is computed as the difference between the predicted word w[t] and the true word w[t].
The loss function is usually the cross-entropy loss, which measures the difference between the predicted probability distribution and the true probability distribution.
Update the weights and biases:
The weights and biases of the forward and backward layers are updated using gradient descent and backpropagation.
Repeat steps 2-5 for all words in the input sequence.
ELMo generates contextualized word embeddings by combining the hidden states of a bi-directional language model (BLM) in a specific way.
The BLM consists of two layers: a forward layer that processes the input words from left to right, and a backward layer that processes the input words from right to left. The hidden state of the BLM at each position t is a vector h[t] that represents the context of the word at that position.
To generate the contextualized embedding for a word, ELMo concatenates the hidden states from the forward and backward layers and applies a weighted summation. The hidden states are combined using a task-specific weighting of all biLM layers. The weighting is controlled by a set of learned weights γ_task and a bias term s_task. The ELMo embeddings for a word at position k are computed as a weighted sum of the hidden states from all L layers of the biLM:
Here, h_LM_k,j represents the hidden state at position k and layer j of the biLM, and γ_task_jand s_taskare the task-specific weights and bias term, respectively. The task-specific weights and bias term are learned during training, and are used to combine the hidden states in a way that is optimal for the downstream task.
Using ELMo for NLP tasks
ELMo can be used to improve the performance of supervised NLP tasks by providing context-dependent word embeddings that capture not only the meaning of the individual words, but also their context in the sentence.
To use a pre-trained bi-directional language model (biLM) for a supervised NLP task, the first step is to run the biLM and record the layer representations for each word in the input sequence. These layer representations capture the context-dependent information about the words in the sentence, and can be used to augment the context-independent token representation of each word.
In most supervised NLP models, the lowest layers are shared across different tasks, and the task-specific information is encoded in the higher layers. This allows ELMo to be added to the model in a consistent and unified manner, by simply concatenating the ELMo embeddings with the context-independent token representation of each word.
The model then combines the ELMo embeddings with the context-independent token representation to form a context-sensitive representation h_k, typically using either bidirectional RNNs, CNNs, or feed-forward networks. The context-sensitive representation h_kis then used as input to the higher layers of the model, which are task-specific and encode the information needed to perform the target NLP task. It can be helpful to add a moderate amount of dropout to ELMo and to regularize the ELMo weights by adding a regularization term to the loss function. This can help to prevent overfitting and improve the generalization ability of the model.