RNN-based Encoder – Decoder
Encoder
An encoder transforms the input data into a different representation, usually a fixed-size context vector. The input data x can be a sequence or a set of features. The encoder maps this input to a context vector c, which is a condensed representation of the input data. Mathematically, this can be represented as:


In the case of a sequence, such as a sentence in a language translation task, the encoder might process each element of the sequence (e.g., each word) sequentially. If the encoder is a recurrent neural network (RNN), the transformation f can involve updating the hidden state h at each step:
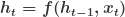



The final hidden state h_T can be used as the context vector c for the entire input sequence.
Decoder
The decoder takes the context vector c and generates the output data y. In many applications, the output is also a sequence, and the decoder generates it one element at a time. Mathematically, the decoder’s operation can be represented as:
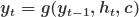

In many sequence-to-sequence models, the decoder is also an RNN, and its hidden state is updated at each step:

The encoder-decoder framework, particularly in the context of sequence-to-sequence models, is designed to handle sequences of variable lengths both on the input and the output sides.
Output Generation (Decoder)
Initial State: The decoder is initialized with the context vector c as its initial state:

Start Token: The decoder receives a start-of-sequence token SOS as its first input y0.
Decoding Loop: At each step t, the decoder generated an output token y_t and updates its hidden state h’_t.
Variable Length Output: The decoder continues to generate tokens one at a time until it produces an end-of-sequence token EOS. The length of the output sequence Y = (y_1, y_2, …, y_m) is not fixed and can be different from the input length n. The process is as follows:


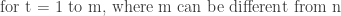
Stopping Criterion: The loop stops when the EOS token is generated, or after producing the maximum allowed length for the output sequence.
The decoder can be also represented using the probability distribution of the next token given the previous tokens and the context vector c from the encoder:
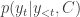
The full sequence probability is the product of individual token probabilities: the decoder generates a sequence token by token, and the probability of the sequence Y given the context vector C can be described by the chain rule of probability:

How do we obtain these conditional probabilities?
– For each time step t from 1 to m (m is to be determined):
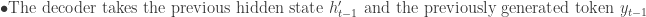

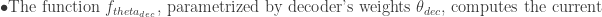


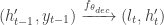

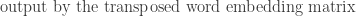

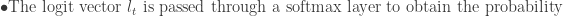
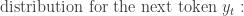

Token Generation:

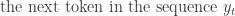

Sequence Continuation:
– This process repeats, with the decoder generating one token at a time, updating its hidden state, and adjusting the probability distributions for subsequent tokens based on the current sequence.
Stopping Criterion:
– The loop continues until the decoder generates an EOS token, indicating the end of the sequence, or until it reaches a predefined maximum sequence length.
